
Rapid deployment of scalable, dense ISR payloads for UAVs
StoryApril 11, 2011

David Pointer
SRC Computers, LLC
In light of increasing demands for advanced rapid prototyping and deployment of ISR applications on UAV platforms, systems engineers would be wise to examine reconfigurable architectures and flexible software tools that match the job's qualifications.
Reconfigurable computing systems are an excellent and increasingly popular choice to provide heterogeneous Digital Signal Processing (DSP) compute solutions for Intelligence, Surveillance, and Reconnaissance (ISR) applications on Unmanned Aerial Vehicles (UAVs). Reconfigurable systems can be created with lower Size, Weight, and Power (SWaP) and higher computational density for an ISR unmanned airframe application compared to other types of systems.
In addition, programming environments are now available using ANSI standard C or FORTRAN, and enable a programmer to extract all possible compute performance from the hardware. The use of standard programming languages greatly reduces the learning curve, enabling much quicker application deployment when compared to programming environments that utilize a proprietary non-standard language or purely hardware languages. Thus, UAV ISR systems developers should consider reconfigurable computing architectures and flexible software tools imperative in their designs.
Reconfigurable computing for UAV payloads
When considering rapid deployment of UAV payloads, reconfigurable hardware is key. At the core of a reconfigurable system is the FPGA integrated circuit. This device may be explicitly programmed to execute application-specific algorithms, and yields very high computational efficiencies relative to a general-purpose device such as a CPU or a General Purpose Graphics Processor Unit (GPGPU). This computational efficiency, in turn, generates high performance per watt for applications executing on reconfigurable systems, which then enables the creation of computationally dense/low SWaP designs for UAV-based ISR applications.
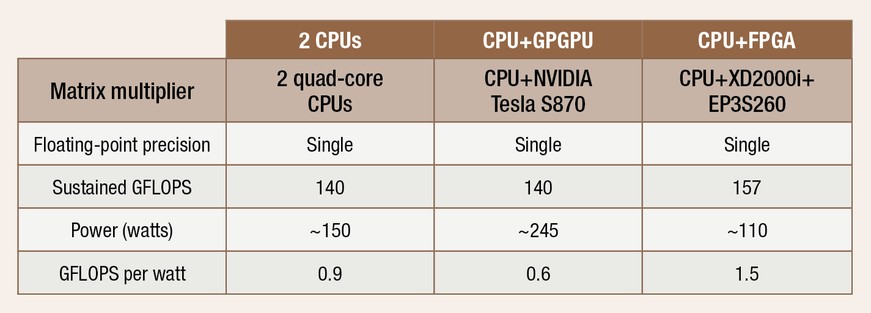
Table 1 compares the execution of a single precision, matrix multiplication benchmark on a CPU-only system, a CPU paired with a GPGPU, and a CPU paired with an FPGA. The reconfigurable system’s performance per watt is 1.7 times better than the CPU-only system, and 2.5 times better than the CPU/GPGPU system. Note the total power consumption for the CPU/FPGA combination is the lowest power consumption.
Table 1: Matrix multiplication performance/power ratio. Source: Altera Corporation, “FPGA Coprocessing Evolution: Sustained Performance Approaches Peak Performance,” WP-01031-1.1, June 2009 version 1.1.
(Click graphic to zoom by 1.9x)
|
|
A major factor in rapid UAV payload deployment is the availability of standard programming tools that are closely coupled with the reconfigurable computer hardware. The piecemeal method of integrating compilers, software tools, FPGA boards, and CPU boards from different vendors slows down deployment. If the tools and hardware have different suppliers, a system runtime environment must be created to unify the system before meaningful application work may begin.
Once real application development finally begins, one vendor’s compiler macro libraries (assuming they do have libraries) will not be optimized for another vendor’s FPGA boards, and so the application development must either experience a reduction in the performance specification or a schedule extension. These and other inherent difficulties in the piecemeal method of UAV payload development conspire to decouple the word “rapid” from “deployment,” usually in an unanticipated manner, and always during application development. Thus, a complete, well-integrated software and hardware package from one supplier is typically the best route for rapidly deploying a UAV payload.
Scalable systems and parallel programming
A modular, scalable system lends itself well to code reuse, which also accelerates deployment for UAV payloads. Modularity in software design allows proven code to be reused across several ISR applications, while hardware modularity supports easy scaling of an ISR application according to mission parameters and a UAV airframe’s SWaP requirements. Most heterogeneous systems today use one form or another of PCIe to give coprocessors access to system memory through the CPU. However, the effective scalability of PCIe is limited by its blocking “many-to-one” architecture (Figure 1). PCIe coprocessors access data and communicate with each other only through system memory on the other side of the CPU. While PCIe does provide point-to-point connectivity through the PCIe switch, one point is always CPU memory and the other point is always a PCIe device. Truly usable scaling requires distributed memory and a switched network with nonblocking, “many-to-many” connectivity to or from any module on the switch.
Figure 1: Typical PCIe-based coprocessor architecture with limited scalability because of its blocking “many-to-one” point-to-point architecture
(Click graphic to zoom by 1.9x)
|
|

A modular hardware system that scales well is only a good start. Software tools must provide the programmer with intuitive or automatic access to the dense computational efficiency in the reconfigurable system. UAV payload development and deployment are impacted if a programmer has to drill down into a system’s architecture to find and develop solutions to meet an application’s performance requirements. There are standard computer languages available for programming the CPU and FPGA in a reconfigurable system, but simply using C or FORTRAN alone will not achieve ISR application performance requirements. C and FORTRAN are serial programming languages traditionally used for CPUs, where instructions are executed serially, one instruction at a time. Performance in a reconfigurable system is achieved by parallel programming: multiple streams of program instructions acting upon multiple streams of data at the same time.
Fortunately, the scientific supercomputing community has already developed parallelization techniques for C and FORTRAN, many of which have been adopted by some reconfigurable system compilers. One method of programmatically specifying parallelism is the OpenMP parallel section pragma statement. On a traditional large cluster of microprocessors, the code blocks enclosed by the parallel section pragma may be executed in parallel on the CPUs. On reconfigurable systems, the code blocks specified by OpenMP-style pragmas are instantiated in the FPGAs so that these “hardware code blocks” execute in parallel. Another method is data streaming, where a series of calculations is overlapped in time; for example, a computational block may start executing when the first results of the previous block are received instead of waiting for all results from the previous computational block to be produced before starting.
Along with parallelization techniques borrowed from scientific supercomputing, most reconfigurable system compilers perform automatic loop pipelining for execution performance. In addition, reconfigurable system compilers automatically create in FPGA hardware all arithmetic operations in a program loop, all of which execute in parallel. Contrast this with a microprocessor compiler, which is limited by the number of arithmetic compute elements available in the CPU’s design. The real issue here is the effectiveness of a given set of software tools for a given system. But software tools do exist to provide programmers of compute-intensive ISR applications access to the potential performance in reconfigurable hardware.
Reconfigurability facilitates rapid deployment, SWaP
Reconfigurable systems and tools are available today for rapid development and deployment of ISR applications. The dense computational nature of reconfigurable systems makes them an ideal choice for solutions where Size, Weight, and Power consumption matters. Software tools closely coupled with the hardware allow software programmers to quickly achieve high performance in a low-SWaP processor payload.
Accordingly, SRC Computers provides modular, scalable, reconfigurable low-SWaP systems with software tools and libraries, using ANSI standard languages for rapid deployment of compute-intensive ISR applications for UAVs. SRC Computers has developed a high-bandwidth, low-latency network switch that provides the necessary non-blocking “many-to-many” module, in addition to data stream constructs for intermodule communication, OpenMP-style pragmas for code block parallelization, and automatic loop pipelining for instruction-level parallelization.
David Pointer is Director of System Applications for SRC Computers, LLC (Colorado Springs, CO). His career spans 30 years in industry and academia, including Hewlett-Packard Laboratories and the National Center for Supercomputing Applications. He holds an M.S. in Electrical Engineering and an M.S. in Computer Science. He may be contacted at [email protected].
SRC Computers, LLC 719-262-0213 www.srccomputers.com




