
VPX in high-performance embedded computing
StoryJuly 16, 2015

Thierry Wastiaux
Interface Concept

Taking advantage of the latest technologies deployed in the commercial high-performance embedded computing environments allow designers to build OpenVPX systems that pack the impressive computing power of tens of GFLOPS while meeting the space and weight limits required in the embedded military and aerospace fields.
In the science field, high-performance massively parallel computing is used in computationally intensive applications such quantum mechanics, weather forecasting, molecular dynamic simulations, aircraft and spacecraft aerodynamics and other physical simulations. The concepts developed in the supercomputing field can be extremely useful in the military domain where it is highly strategic to pack more computing power into smaller sizes. This is particularly true in high-end signal intelligence (SIGINT), radar, electronic warfare (EW), search, and track applications that have very demanding computing requirements. In high-performance embedded computing systems (HPEC), the speed and the flexibility of the interconnect has become a key factor. The VITA 65 OpenVPX standard clearly appears to be the best standard to bring this connectivity while also enabling maximum processing power in small form factor parallel computing architectures.
Bringing the best from the supercomputing world and adapting it to the military and aerospace domain is clearly a challenge.
Processors and FPGAs for HPEC
The choice of the best possible processors and FPGAs to design powerful DSP boards is the first key element on the road to powerful HPEC architectures. These boards have to propose the best ratios in terms of number of operations per second and per watt. The last generations of Intel Core I7 and Xeon DE processors offer an excellent balance between processing power and energy consumption. Moreover FPGAs are known for offering the best ratio of GOPS/W. On integer operations and for parallel computing, they can run ten times faster than a processor which is extremely useful in image processing or signal processing applications. The Xilinx 7 series of Xilinx is one of the best FPGAs for these functions.
In terms of communication capabilities, Intel Core I7 processors feature many native PCI Express (PCIe) links offering tremendous data connectivity. Additionally, Intel Xeon DE processors have integrated 10/40 Gigabit Ethernet ports. Xilinx Virtex-7 FPGAs feature smartly designed transceivers reaching a data rate per lane of as much as 13 Gb/s with an aggregate bidirectional transceiver bandwidth of as high as 2.7 Tb/s. Tightly coupling processors to FPGAs enable the design of very dense and powerful processing boards that are the foundation of HPEC systems.
Small and distributed HPEC systems
Enabling supercomputing in an embedded system depends on the size of the targeted computing system. The interconnect of these systems has to be robust, fast, flexible and very power efficient. Intel has invested massively in the specification and the implementation of the packet high data rate, point-to-point link PCIe protocol. CRC control at the link layer as well as retransmission hardware mechanisms enable robustness and the permanent investment to increase speed has led to very high throughputs.
The maximum theoretical bandwidth per lane is 7.88 Gb/s in Gen3 thanks to the reduced overhead allowed by the 128B/130B encoding. That is a throughput of 31.5 Gb/s on a PCIex4 link. By putting in parallel, various numbers of lanes, high flexibility can be enabled in the system design. Thanks to hardware implemented low power management features, PCIe is a particularly power efficient standard.
Due to the point-to-point nature of the protocol, the industry has designed many switch components that have DMA engines for fast data transfers. The switches can be distributed on the different boards in the systems or set in a centralized switch slot, switching both Control Plane and Data Plane. The Cometh4410a VPX 3U switch from Interface Concept is an example of this kind of implementation, but is limited due to the low number of ports it offers. Thus, PCIe appears as a leading candidate to become the defacto standard interconnect for HPEC systems.
In the PCIe architecture, each Intel processor is the root complex in its PCIe domain enumerating all the end points. Enabling parallel processing in HPEC systems means developing software allowing seamless communication between processors.
Interface Concept has developed a software package, called Multiware, that is able to transparently configure the hardware and the DMA engines of the switches and enables DMA transfers, message passing, and synchronization between the nodes of a HPEC system. In radar or EW HPEC systems this approach enables the inclusion of front-end processing FPGA modules that are directly connected to multiple sensors.
Enabling HPEC systems
PCIe is a point-to-point link protocol and when more parallel processing power is required with a high-speed dataplane over 10 GbE, the PCIe protocol becomes more complex to use. Reaching 10 Gb/s therefore cannot be achieved on only one lane in PCIe Gen3 and a PCIe Fat Pipe Gen3 cannot reach 40 Gb/s.
However, the IEEE 802.3 Standard for Ethernet Sections 4 and 6 from 2012 specifies new standards including 10 GBASE-R and 40 GBASE-R with their physical layer implementations for backplane communication based on 64B/66B code, 10 GBASE-KR, and 40 GBASE-KR4. The 64B/66B code of the Physical Coding Sublayer (PCS) enables robust error detection. Its encoding ensures that sufficient transitions are present in the PHY bit stream to make clock recovery possible at the receiver. The Physical Medium Dependent Sublayer (PMD) of 10 GBASE-KR allows transmission on one lane at 10.325 Gb/s, while the PMD sublayer of 40 GBASE-KR4 allows transmission on four lanes at the same rate.
The use of 10 GBASE-R and 40 BASE-KR4 brings back simplicity by enabling centralized switched architectures. The Cometh4510a is an example of a 10/40 GbE switch corresponding to the OpenVPX Switch Profile MOD6-SWH-16U16F-12.4.5-4. Its dataplane uses the last generation of Marvell Prestera CX platforms, while the control plane uses the well proven Ethernet packet processors of the Cometh4340a switch family. It features 16 ports 1000 BASE-KX on the control plane and 16 40 GBASE-KR4 ports or 48 10 GBASE-KR ports on the dataplane, thus offering a huge switching bandwidth.
A multicore PowerPC management processor running the Switchware package offers two out-of-band 1000 BASE-T ports and allows traffic-log recording on NAND flash. In addition, a custom mezzanine can bring either two 10 GBASE-T ports at the front and two 10 GBASE-KX4 ports on P6, or four 10 GBASE-T ports at the front.
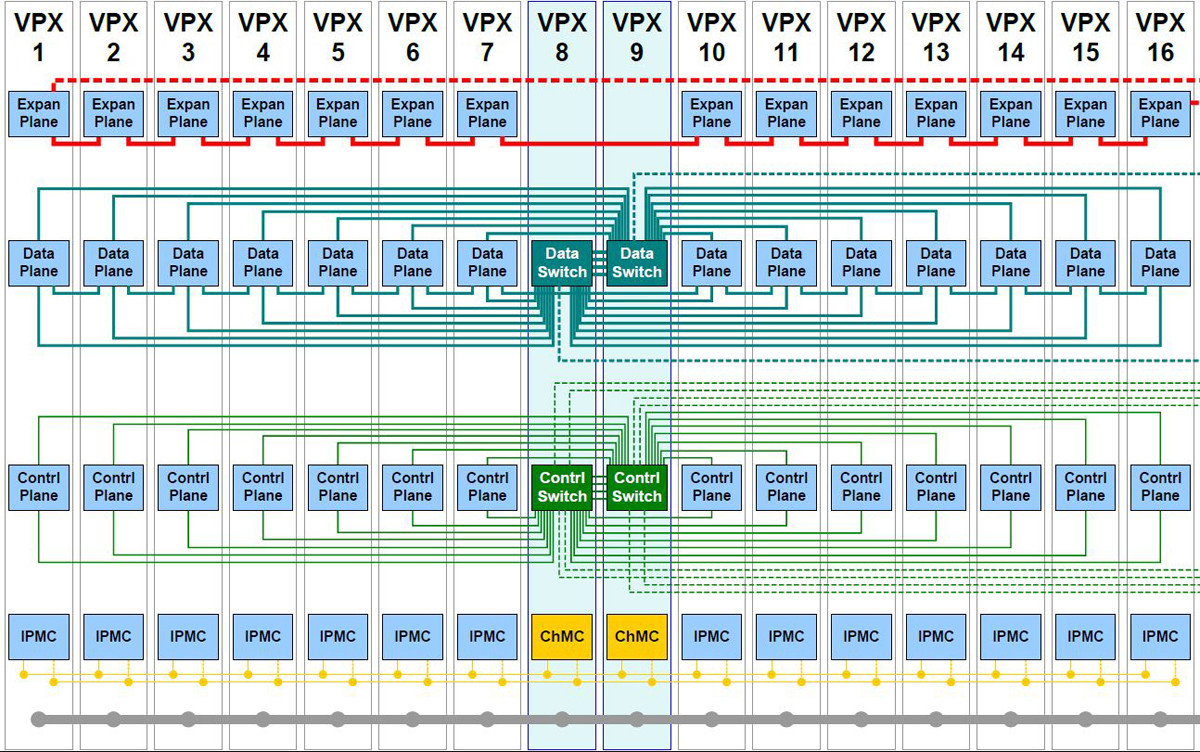
The 10/40 GbE switch is the keystone for building HPEC systems, enabling gathering in parallel as many as 48 DSP boards in 10 GbE and up to 16 DSP boards in 40 GbE. An example of possible cluster architecture is seen in Figure 1 with redundancy switching.
Figure 1: Example of a 14 payloads architecture with redundancy switching.
(Click graphic to zoom)
|
|
Designing HPEC clusters under extended temperature range is a challenge in terms of both heat density and signal integrity. Developing dense multicore DSP boards with communication data rates on differential pairs at more than 10 Gb/s requires the use of the last generation of electromagnetic simulation tools to control the impedance of links through the board and also of specific lab equipment for ensuring signal integrity.
New manufacturing processes insuring impedance control on multilayer PCBs must be well-mastered. Heat management also requires the right simulation tools to ensure efficient heat extraction.
Thierry Wastiaux is Senior Vice President of Sales at Interface Concept, a European manufacturer of electronic embedded systems for defense, aerospace, telecom, and industrial markets. He has 25 years of experience in the telecom and embedded systems market, having held positions in operations, business development, and executive management. Prior to joining Interface Concept, he was responsible for the operations of the Mobile Communication Group and the Wireless Transmission Business Unit in Alcatel-Lucent. He holds an M.Sc. from France’s Ecole Polytechnique. Readers may contact him at [email protected].
Interface Concept
www.interfaceconcept.com




