
Cache partitioning increases CPU utilization for safety-critical multicore applications
StoryMarch 12, 2013

Tim King
DDC-I

Cache partitioning reduces worst-case execution time for critical tasks, thereby enhancing CPU utilization, especially for multicore applications.
One of the biggest challenges facing developers of certifiable, safety-critical software applications for MultiCore Processors (MCPs) is managing access to shared resources such as cache. MCPs significantly increase cache contention, causing Worst-Case Execution Times (WCETs) to exceed Average-Case Execution Times (ACETs) by 100 percent or more. Because safety-critical developers must budget for WCETs, tasks on average (critical and noncritical) are allocated more time than they need, resulting in significantly degraded CPU utilization. One way to address this problem is to utilize an RTOS that supports cache partitioning, which enables developers to bound and control interference patterns in a way that alleviates contention and reduces WCETs, thereby maximizing available CPU bandwidth without compromising safety criticality.
Cache contention
In a simple dual-core processor configuration (Figure 1), each core has its own CPU and L1 cache. Both cores share an L2 cache. (Note that shared memory and optional L3 are not shown.)
Figure 1: Dual-core configuration without cache partitioning
(Click graphic to zoom by 1.9x)
|
|
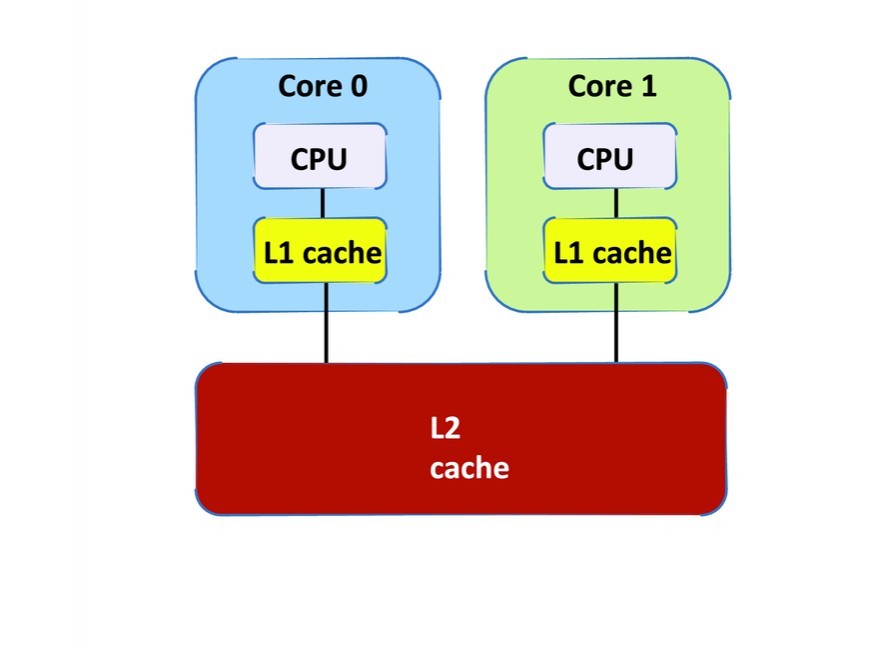
In this configuration, applications executing on Core 0 compete for the entire L2 cache with applications executing on Core 1. (Note that applications on the same core also compete with one another for L2; cache partitioning applies in this case as well.) If application A on Core 0 uses data that maps to the same cache line(s) as application B on Core 1, then a collision occurs.
For example, suppose A’s data resides in L2; any accesses to that data will take very few processor cycles. But suppose B accesses data that happens to map to the same L2 cache line as A’s data. At that point, A’s data must be evicted from L2 (including a potential “write-back” to RAM), and B’s data must be brought into cache from RAM. The time required to handle this collision is typically charged to B. Then, suppose A accesses its data again. Since that data is no longer in L2 (B’s data is in its place), B’s data must be evicted from L2 (including a potential “write-back” to RAM), and A’s data must be brought back into cache from RAM. The time required to handle this collision is typically charged to A.
Most times, A and B will encounter such collisions infrequently. In those cases, their respective execution times can be considered as “average case” (ACET). However, on occasion, their data accesses will collide at a high frequency. In these cases, their respective execution times must be considered as “worst case” (WCET).
When developing certifiable, safety-critical software, one must budget an application’s execution time for worst-case behavior. Such software must have adequate time budget to complete its intended function every time it executes, lest it cause an unsafe failure condition. The safety-critical RTOS must enforce time partitioning, such that each application has a fixed amount of CPU time budget to execute.
With the potential for multiple applications on multiple cores to generate contention for L2 cache, WCETs on MCPs often are considerably higher than ACETs. And since certifiable, safety-critical applications must have time budgets to accommodate their WCETs, this situation leads to a great deal of budgeted but unused time, resulting in significantly degraded CPU utilization.
Cache partitioning
Cache partitioning increases CPU utilization by reducing WCETs, thereby reducing the amount of time that must be budgeted to accommodate WCETs. Again, in a simple dual-core processor configuration (Figure 2), each core has its own CPU and L1 cache and both cores share an L2 cache.
Figure 2: Dual-core configuration with cache partitioning
(Click graphic to zoom by 1.9x)
|
|

In this configuration, the RTOS partitions the L2 cache such that each core has its own segment of L2, meaning that data used by applications on Core 0 will only be cached in Core 0’s L2 partition. Similarly, data used by applications on Core 1 will only be cached in Core 1’s L2 partition. This partitioning eliminates the possibility of applications on different cores interfering with one another via L2 collisions. Without such interference, the deltas between application WCETs and ACETs often are often considerably lower than is the case without cache partitioning. By bounding and controlling these interference patterns, cache partitioning makes application execution times more deterministic and enables developers to budget execution time more tightly, thereby keeping processor utilization high.
Test environment and applications
To demonstrate the benefits of cache partitioning, DDC-I used Deos (its certifiable, safety-critical, time- and space-partitioned RTOS) to run a suite of four memory-intensive test applications, all with a range of data/code sizes, sequential and random access strategies, and various working set sizes:
- Read only
- Write only
- Copy
- Code execution
The tests were performed on a 1.6 GHz Atom processor (x86) with 32 KB of L1 data cache, 24 KB of L1 instruction cache, and a 512 KB unified L2 cache. Note that while a single-core x86 processor was used for these tests, Deos’ cache partitioning capability applies equally well to applications executing on the same core (which also compete for L2). Further, it does not depend on any features that are special or unique to x86 processors and applies equally well to other processor types (such as ARM or PowerPC).
The tests were run with and without a “cache trasher” application, which evicts test application data/code from L2 and “dirties” L2 with its own data/code. In effect, the cache trasher puts L2 into a worst-case state from a test application’s perspective. That is, the cache trasher mimics real-world scenarios, where different applications run concurrently and compete for the shared L2 cache.
Each test application was executed under three scenarios. In scenario 1, which is conducted without cache partitioning or cache trashing, the test application competes for the entire 512 KB L2 cache along with the RTOS kernel and a variety of debug tools. This test establishes baseline average performance, wherein each test executes with an “average” amount of L2 contention.
In scenario 2, which uses no cache partitioning, the test application competes for the entire 512 KB L2 cache along with the RTOS kernel, the same set of debug tools used in scenario 1, and a rogue cache trasher application. This test establishes baseline worst-case performance, wherein each test executes with a worst-case amount of L2 interference from other applications, primarily the cache trasher.
In scenario 3, which uses cache partitioning and cache trashing, three L2 partitions are created:
- A 256 KB partition allocated to the test application
- A 64 KB partition allocated to the RTOS kernel and the same set of debug tools used in scenarios 1 and 2
- A 192 KB partition allocated to the rogue cache trasher application.
This scenario establishes optimized worst-case performance, wherein each test executes within its own L2 partition with no interference from other applications, including the cache trasher.
Cache partitioning results, benefits
Figure 3 shows the results for the read-only test application.
Figure 3: Cache partitioning impact on read-only tests
(Click graphic to zoom by 1.9x)
|
|

For example, with no cache partitioning and no cache trashing (scenario 1, ACET), the read-only test averaged 105 microseconds per execution given a working set size of 512 KB. In scenario 2 (WCET with no partitioning, cache trashing added), the test averaged 400 microseconds per execution for the same 512 KB working set, a 280 percent increase. When cache partitioning is added (scenario 3, WCET with cache trashing), the average execution time drops to 117 microseconds, or just 11 percent higher than the ACET.
These results demonstrate the efficacy of cache partitioning for an application that performs a large number of reads per period. Though difficult to discern here due to differences in magnitude, the impact on bounding WCETs is more pronounced when the application’s working set size fits within the cache partition that it’s using (in this case, 256 KB). This result is expected because of the nature of cache. That said, embedded, real-time applications tend to have relatively small working set sizes, so we expect that cache partitioning will benefit most applications.
Results for the write-only test were similar to the read-only test, though more pronounced for smaller working sets. For larger working sets, results showed relatively small differences between WCETs with and without cache partitioning.
Results for the copy test were similar to the read-only test, though more pronounced for smaller working sets. For larger working sets, results were less dramatic, but still showed significant improvement (roughly 2x) in WCETs with cache partitioning.
Results for the code execution tests were similar to the read-only test, though somewhat less dramatic.
Note that it is possible for applications executing in the same cache partition to interfere with each other. However, such interference typically is much easier to analyze and bound than the unpredictable interference patterns that may occur between applications executing on different cores with shared cache. In those situations, if interference is unpredictable, then applications could be mapped to separate cache partitions.
The benchmark results clearly demonstrate that cache partitioning provides an effective means of bounding and controlling interference patterns in shared cache on an MCP. In particular, WCETs can be bounded and controlled much more tightly when the cache is partitioned. This allows application developers to set relatively tight, yet safe, execution time budgets, thereby maximizing MCP utilization.
Of course, results will vary for different applications and hardware configurations, and additional RTOS capabilities will be required to successfully certify safety-critical MCP-based systems. Regardless, these results represent a significant advancement toward the goal of using MCPs to host certifiable, safety-critical applications.
Tim King is the Technical Marketing Manager at DDC-I. He has more than 20 years of experience developing, certifying, and marketing commercial avionics software and RTOSs. Tim is a graduate of the University of Iowa and Arizona State University, where he earned master’s degrees in Computer Science and Business Administration, respectively. He can be contacted at [email protected].
DDC-I 602-275-7172 www.ddci.com




